
AA: Scraping Data Off The Bot Store (Part-II)

In last week’s post, we developed the navigation…well most of it.
Where Did We Go Wrong This Time?
Nowhere.
We are on the right track and only have to include one more condition into the Loop: While Action, to ensure it works as expected.
I didn’t include this in the previous post as it breached the 1000-word limit.
Lets hope I won’t breach that limit today, or I might end up having to write another article for this series(spoiler alert: I did).
Tell Us More About This Mystery Condition
No.
What Do You Mean “No”?
If I tell you now, you won’t get it.
We will march back into data scraping and then make our way back to the condition.
This transition helps, since we will be using some of the Xpaths we are about to dive into, for our Loop:While Action.
Elements to Extract
Let’s have a look at the items we wish to extract.

Green – Title
Blue – Hyperlink
We will extract them one by one, using Xpaths.
Gotta Categorize It First!
Like before, hover over the element you wish to extract, right click and press inspect.
Once the window pops up, analyze the HTML tag and attribute for the Category we are about to extract.
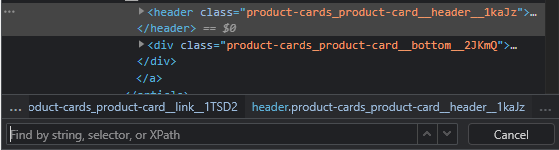
Web elements are often enclosed in parent elements such as spans and headers and sometimes the inspection doesn’t narrow it down to the exact element which represents it, so we have to inspect it a couple of times, or highlight the element and see if it matches the element exactly.
Once you narrow it down to the right HTML tag, you can start crafting your Xpath.
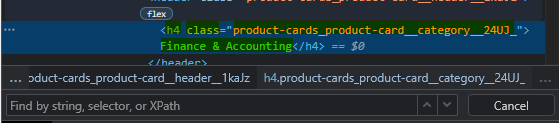
Remember what we did last time?
We first added two forward slashes, followed by the tag name.
//h4This will identify all h4 tags present on the webpage, and to narrow it down to the element we want to extract, we have to chain an attribute or two to it.
Looky here, there is a class attribute. Let’s try adding that to our Xpath and see what turns up.
//h4[@class='product-cards_product-card__category__24UJ_']
It is able to identify all the items we need on the page!
How Will Our Bot Extract Them?
Now that we have our Xpath, all we have to do is to develop the logic and intertwine it with our Bot Logic.
The Xpath has identified all the required elements, but our bot can only loop one record at a time.
A slight modification will be required here, both for the Xpath as well as for the Bot Logic.
We will reference each item by enclosing the Xpath within curved brackets and add a number enclosed in square brackets towards the end of the Xpath as shown below:
(//h4[@class='product-cards_product-card__category__24UJ_'])[2]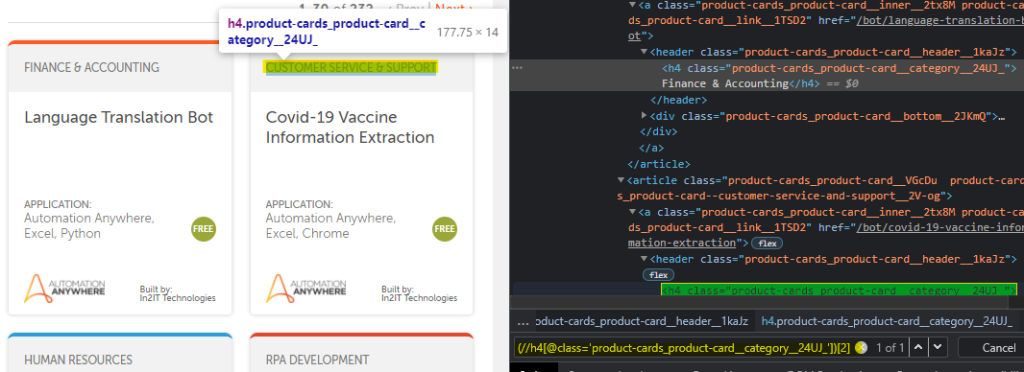
Do you see where I am going with this?
The Bot loves operating with loops, and now that the Xpath has been broken down into digestible segments, all that’s remaining is to declare a counter and add it to our Xpath.
(//h4[@class='product-cards_product-card__category__24UJ_'])
[$nCounter:Number.ToString$]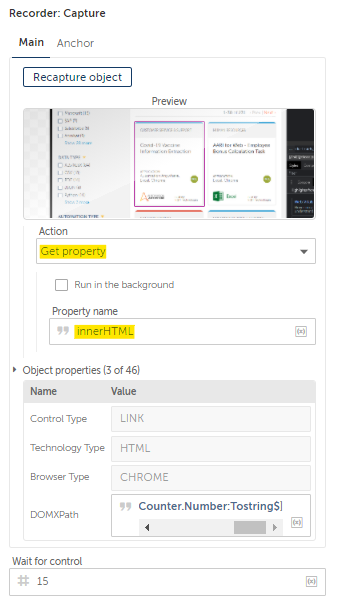
And with that, we have extracted all the categories.
Similarly, other elements are also extracted…except you will face an issue while trying to extract the Hyperlink.
And no, I am not going to explain how I extracted the hyperlink.
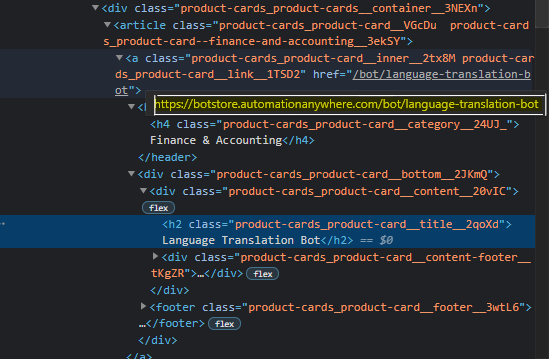
Take it as a challenge and see if you can locate the element and craft the Xpath in such a way that the Bot retrieves the Hyperlink and not everything under that particular node.
Coming Back To Our Beloved While:Loop
We have three well defined Xpaths, and only have to choose one of them.
I’ve noticed, that the category for few of them are missing, while the Titles are all present, so I will use the Xpath for Title as an additional Loop:While -> Recorder: Object Condition.
Wait Wait, Why Are You Doing That?
While iterating through each page, as soon as the bot reaches the last page it will cease scraping.
This happens because the Next Button is no longer active, which tells our Bot to break out of the loop.
To avoid this, we will include the Item Xpath as a condition to ensure that doesn’t happen.
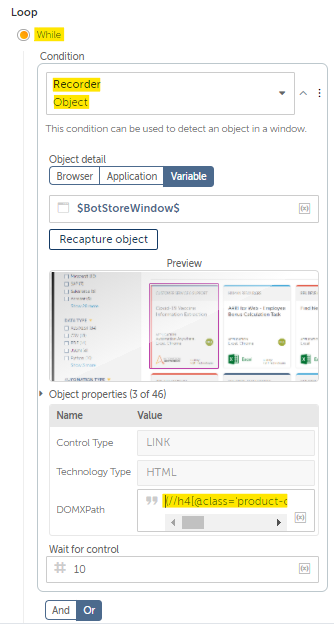
And how will we chain the conditions?
Should the Title AND Next Button Exist at the same time, OR only either one should be present at a given time?
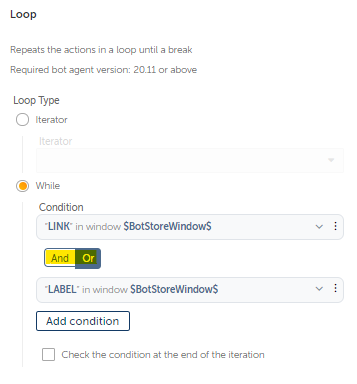
I think the item condition alone would suffice, but just to be sure I have included two conditions.
You Thought We Were Done?
Even after all of what we have done so far, we will still run into errors.
We know for a fact that each page contains results lesser than or equal to 30.
Our counter will go on incrementing, even after the bot heads over to the next page.
So we have to add in an If Action: Number Condition to check whether the counter is equal to or greater than 30.
Inside the If Block, the next button is clicked and the counter is reset to one.
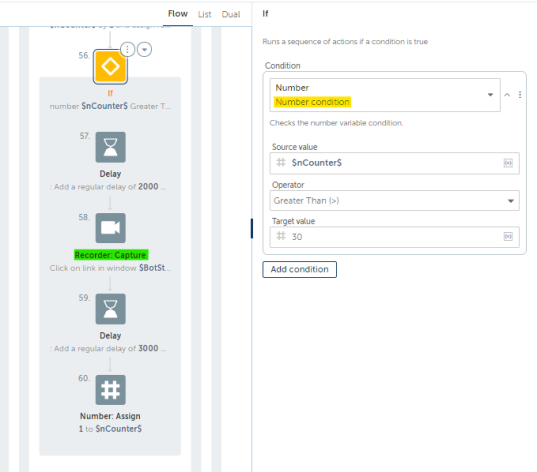
This is done, because the only time it will enter the If Block is when the bot is currently scraping items from the last item on that page. Its 30 items per page, and this is how you teach the bot.
You might have to run few tests on your own.
I haven’t detailed the entire process, just the core aspects of the data scraping.
The progress you make from hereon is entirely dependent on you and the effort you are willing to put into learning.
Nope, We Still Aren’t Done
After reviewing the automation I developed, I because a little creative and added a couple of enhancements.
We will explore it next week.