
AA: Scraping Data Off The Bot Store (Part-I)
Automation Anywhere at its core consists of a series of scripts bundled up into click and drag Actions, which is bundled up even further into Packages and finally bundled up into an end to end SaaS called Automation 360.
And that’s not all.
With a little bit of Java, you too can create your own custom packages. We will explore one such example in a coming article, for now let’s head back to the topic at hand.
Topic I Drifted Away From Before We Even Had a Chance To Start
While Python is good at automating the boring stuff, RPA is better at automating the boring stuff.
With RPA, you may develop and execute automations in less time it would take to develop and test scripts.
You aren’t staring into the abyss and fretting over each line of code hoping that if you stare long enough, it will start working.
Scripts run on concrete logical networks, not Harry Potter magic.

Its Coding.
Automation Anywhere is not limited to backend automations.
It goes up and beyond, and can be leveraged for a multitude of diverse operations.
We will explore one of those operations today.
Will The Government Hate Me For This?
As long as you aren’t hacking into government portals and scraping data off their server, which by the way is a great way to challenge yourself and end up on television for all the wrong reasons, Data Scraping is not going to get you into any sort of trouble.
But the question we ask ourselves first is,
Why Scrape Data In The First Place?
The internet is an ocean of information.
There you will find data pertaining to real estate, products, retail etc, most of which are crucial for analytics or for making informed business decisions.
Nobody purchases a House without negotiating first, but to be in a position to negotiate, you have to do your homework.
No one bases their financial decisions entirely on gut instinct. That isn’t what we’d term as an “investment”.

RPA is great for Data Scraping because it doesn’t take as much time to develop and maintain.
But it’s not as easy as it sounds, because to scrape data, you have to understand the sub-processes and techniques involved, which is why I wrote this.
I will guide you through a simple-ish exercise which involves scraping data off the Automation Anywhere Bot Store.
Process:
Say you wish to scrape the details of bots which perform automations with Excel Spreadsheet.
You have to navigate to the Right Page, keep track of the Number of Pages and Number of Items per page.

If there are 232 results for Excel Bots, and each page contains 30 items, the bot has to click Next only 8 times.
It’s your task to develop the logic for that.
Think about it for a while before proceeding.
.
.
.
.
.
Have You Thought About It?
You may either Capture the Total number of items, divide it by 30 and plug the output into a Loop: For n Times…
Or you could do something even smarter.
Something Even Smarter?
Something even smarter.
HTML elements are threaded together as a collection of tags and attributes, many of which change depending on its “state”. You don’t have to worry too much about what that means for now, just think of it as a property which is responsible for enabling or disabling elements.
To navigate to the next page, you have to press Next. Once you reach the last page, the button greys out (state changes, hence the object gets rendered), and one or more of the button properties changes.
This is going to come in handy.
We will capture the Button using the Loop toggled to While: Object when it is active, and nest a Recorder: Capture Action which references the same Button.
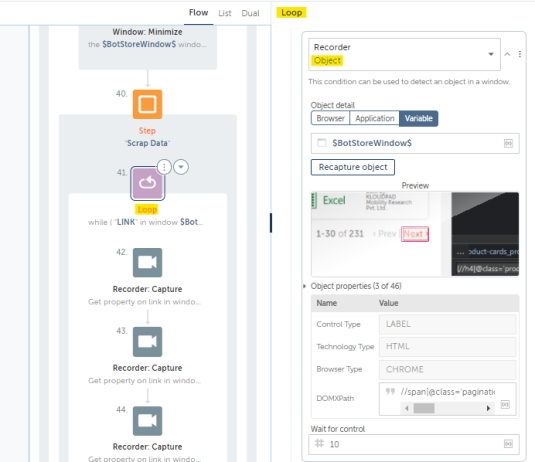
The Loop with iterate as long as the button is present. That is the benefit of using a Loop:While.
With this, we are now able to navigate across all pages.
But Wait a Minute
What were we trying to achieve here?
Was the bot being sent on a business trip, or on a vacation?
Weren’t we trying to scrape data off each page?
Well, this is where it gets kinda complicated.
XPaths Aren’t That Complicated, But Yeah.
Yes, you need to dabble in some slightly technical stuff when dealing with web automations.
Don’t worry, these are one of the few instances where you have to dip your toes into the not-too-technical waters.
You don’t have to become an XPath diving professional to use them.
The basics will suffice.
What Are XPaths?
Xpaths are what we use to query elements from an XML document.
Simply put, anything that is contained within a hierarchy can be queried using Xpaths.
Web pages is represented by DOM which isn’t exactly an XML. XML defines hierarchy, while DOM describes the relation between the elements within the hierarchy, but let’s not get into any of that.
A webpage is a collection of web elements, and each element shares a hierarchical relation within the Document Object Model.
The element we want from the hierarchy can be retrieved either by directly referencing the element, or by using “shortcuts” called Xpaths.
Xpaths are called shortcuts (or that’s what I call them) because they do a pretty good job of filtering data without having to provide too much detail.
Absolute paths aren’t ideal since it requires us to specify the entire path extending from the root of the HTML. Xpaths reduces the length of the query, making them more dynamic, easier to develop and rectify.
We captured the Next Button earlier didn’t we?
Head over to the Object Properties and search for the Object Property which tells us whether it is active or not.
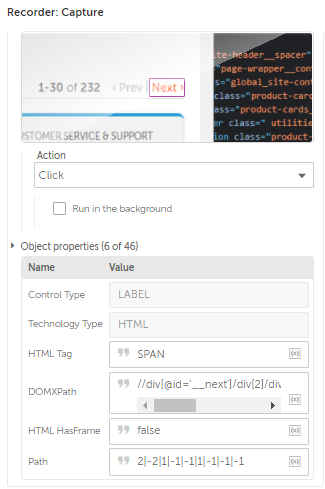
If you can’t tell the difference, try capturing the button while it is inactive (Head over to the last page) and compare the properties.
Try it out now.
Go on, head over to the Bot Store and see if you were able to figure it out.
.
.
.
.
.
Were You Able To Figure It Out Yet?
The property highlighted below is the one that changes.
pagination_pagination-v2__item__bn9Hx pagination_is-disabled__2XM45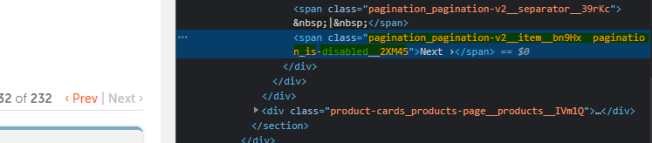
So, how are we going to leverage this property to our advantage?
Good question.
You might have noticed, there is a property called DOMXpath.
Automation Anywhere is smart enough to pull out the path for us, but it isn’t smart enough to refine it. Sometimes, the auto-generated path is spot on, but for the most part, our intervention is necessary.
That is when Xpaths come into the picture.
Lets have a look at the auto-generated DOMXpath for a moment.
//div[@id='__next']/div[2]/div[1]/div[1]/section[1]/div[1]/div[2]/div[1]/span[3]This is the path our Recorder: Capture Action came up with.
It won’t be used here, as it contains elements that don’t behave as proper indicators.
We have to find a way to wrap up the property which indicates its state into an Xpath that uniquely identifies the Next Button.
Lets Do That!
Position your cursor over the element you wish to piece apart, then right-click and press inspect.
Once that’s done, a sub tab pops up onto display, showing us the skeletal structure of the page.
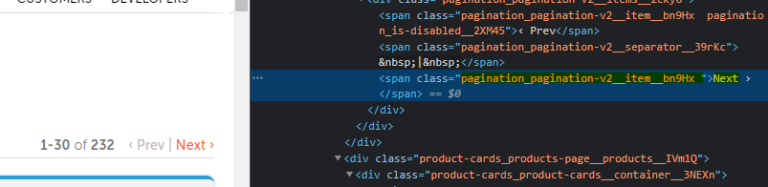
If the element we tried to inspect didn’t highlight as shown above, you may use the button present on the top left-corner, or simply right-click and inspect it once more.
Now that the element has been highlighted, let’s take a closer look.
We can see that the element in enclosed inside of a span, and identified by a class. The span and class are referred to as tag and attribute respectively.
Xpath are initialized with two forwards slashes, followed by the parent node name which in this case is span.
//span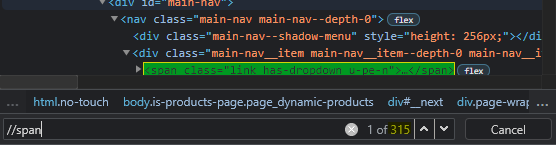
With this, we have identified all the span items on the webpage, which is NOT what we were looking for.
Let’s narrow our search down even further, using the class attribute from earlier.
//span[@class='pagination_pagination-v2__item__bn9Hx ']
Attributes are referenced using the at symbol. Its contents are fed into the Attribute within single quotations as shown above.
But what is this? Two matches? How is that possible?
Well that’s because there are two Next Buttons – one on top and the other below.
You can go for either one.
I will be identifying the Button present on top using this:
(//span[@class='pagination_pagination-v2__item__bn9Hx '])[1]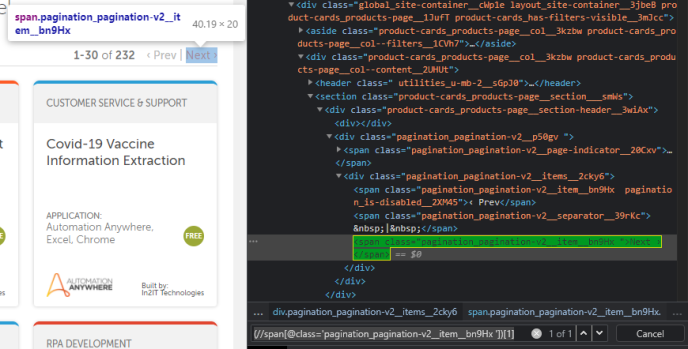
And that is how you incorporate relevant properties into your DOMXpath.
We will stop here for today.
I’ve long since breached the 1000-word limit and if I go on any further then you will tire out.
Chances are you aren’t even reading this.

We will continue this next week, where we will develop Xpaths for the items we want to extract and wrap it up from there(Hopefully).