
AA: Extracting Tables That Aren’t Tables(Part-I)
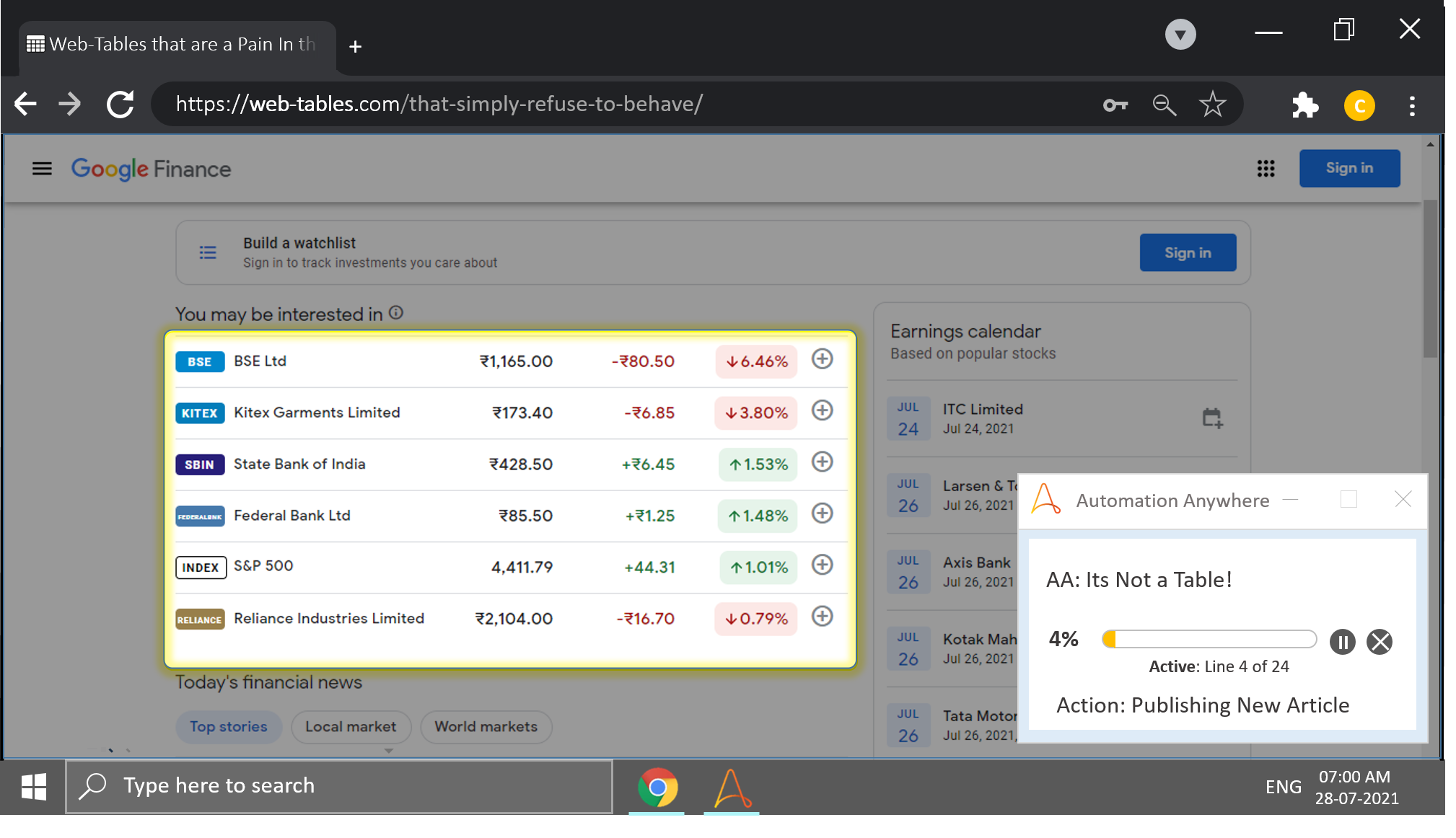
In the vast uncharted waters of the Internet, there exists a special breed of web tables which possess all characteristics of a table, except that it stem from different ancestral HTML roots.
Automation Anywhere recognizes them, but records them under a CLIENT control, and it pisses the living daylights out of me whenever that happens.

That being said, you won’t always come across this HTML nightmare, but in case you do, you have this article to rely on.
Why This Is Difficult
The table data isn’t stored between table tags, which is why the Recorder: Capture Action is unable to save it as a Table.
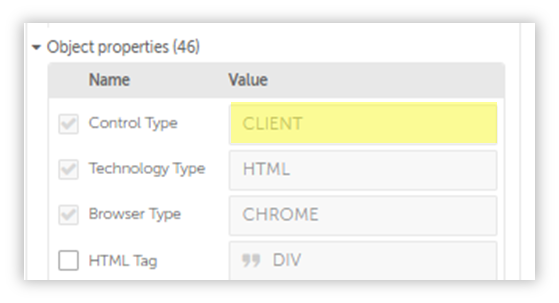
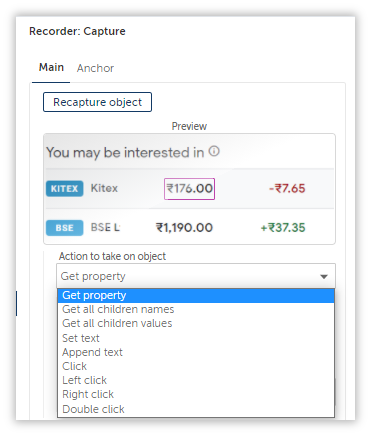
If the data was stored between table tags, then our Recorder: Capture Action would have allowed us to capture it as a table in one go.
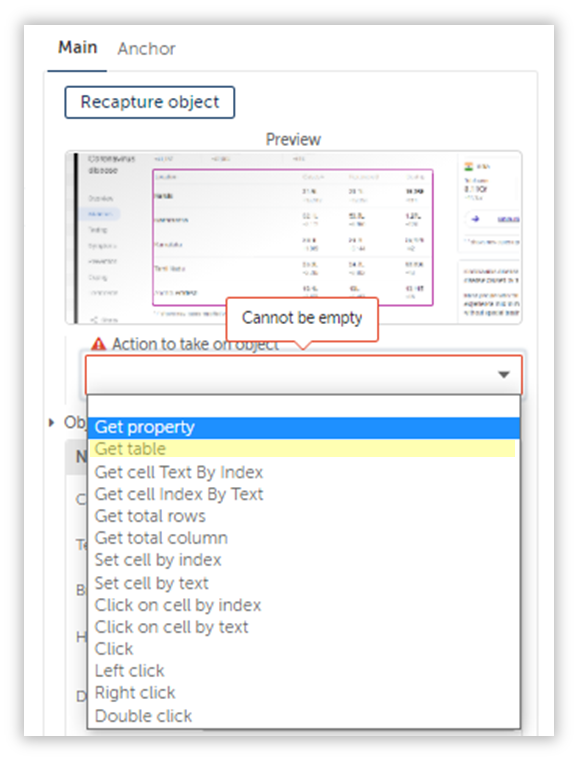
So what can be done?
How will we capture the table?
We can’t right, so what other option do we have?
Can we sweep it under the rug and hope our manager won’t find out?
Good luck with that last suggestion.

Where There is a Will, There Is a Way
But that way is paved with Xpaths.
Lots and lots of Xpaths.
Lucky for you, I have come up with a solution that works.
If this is new to you, then check out my series on Datascraping.
I’ve used Xpaths there, and it will help you get an idea of what Xpaths are, and how we can craft them.
However…
You can’t achieve a solution just by copying what I’ve done here.
Simply applying the exact same steps won’t cut it, because to make it work, you have to first study the HTML container housing the data you wish to extract, and study it well.
I can’t stress this enough, without adequate Xpath knowledge, you won’t be in a position to develop workflows reliable enough to extract data from HTML elements such as these.
So explore as many concepts on Xpaths as you possibly can, before moving onto advanced data manipulation.
Now that I’m done scaring you, lets dive in.
Google Finance
This can be accessed here.
The goal of our automation is to scrap data from the pseudo-table and arrange that data in tabular format i.e., scrap the data, and store it into a Table Variable.
Here is a screenshot to shine some Vitamin D onto the topic at hand.
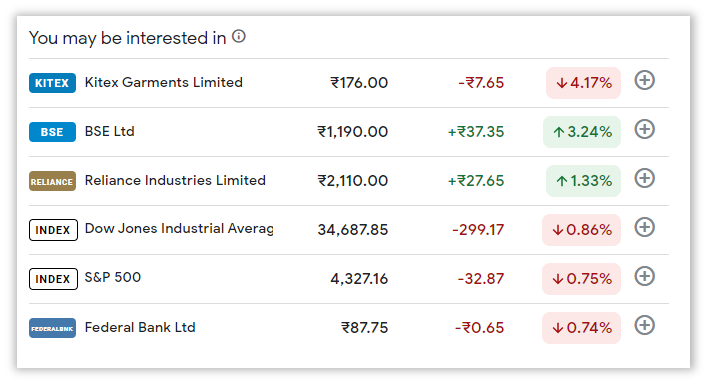
The Solution Can Wait
Before we explore the solution, first let’s inspect the elements.
Like I mentioned earlier, unless we understand the skeletal structure of HTML, we will continue paddling about aimlessly in its black waters, waiting for death(cough* Project Manager cough*) to release us from our misery.
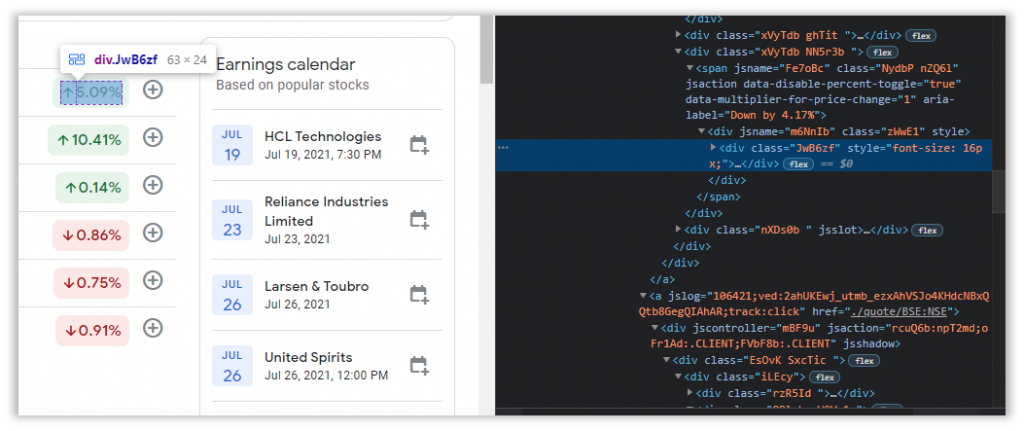
What have you understood from analyzing the HTML tags?
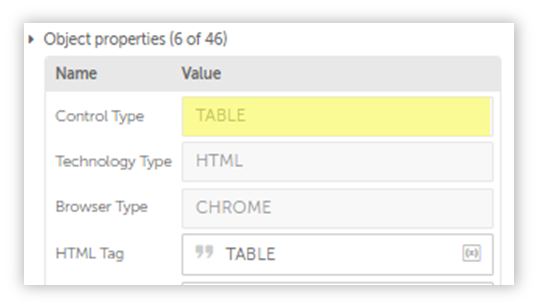
They are DIV tags nested within DIV or SPAN tags.
In short, they are not TABLE tags.
This is why our Recorder is unable to detect the table.
I tried referencing the cells one by one using just the class attribute, but the class wasn’t unique just to that particular table. It detected elements outside the Table, so to overcome this, I came up with an idea I borrowed from regex. I will first anchor onto the parent tag and then travel towards the desired element.
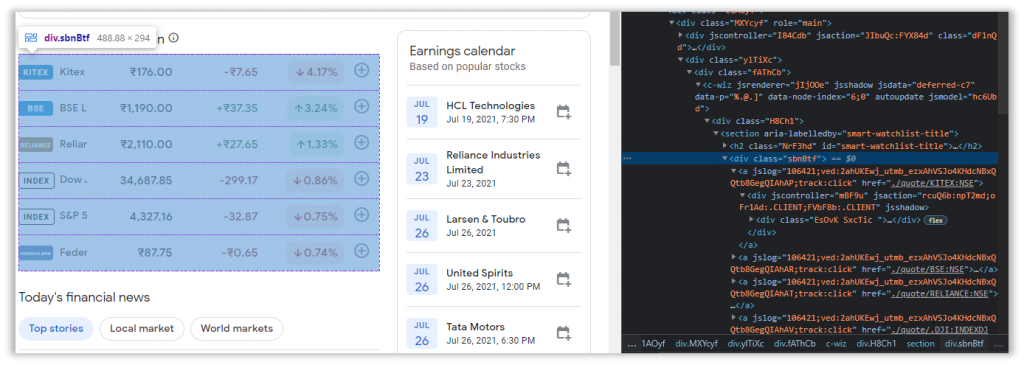
After inspecting one of the elements and travelling backwards, we have successfully pinpointed the parent element.
//div[@class='sbnBtf']This is crucial, as it will behave as our starting point.
You can think of this as our starting point, through which all the other elements pertaining to each individual column will be retrieved from.
I am repeating this over and over so that you will internalize whatever is being presented here.
Now, we will use Xpaths to construct a network of logic to retrieve the items for each column.
For Each Column?
Yes, for each column.
This is a bit tedious, but it gets easier with practice.
Let’s start with the first column.
As mentioned earlier, we will start from our anchor and inch our way across each node, until we find the item we are interested in, which in this case is the Company Name(Stock).
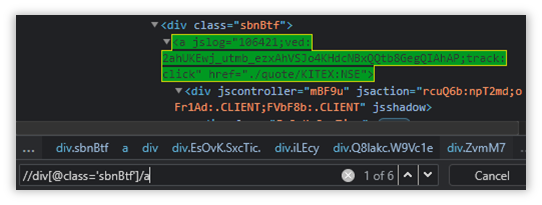
//div[@class='sbnBtf']/aThis has detected all six blocks, but that is not what we want.
We have to identify the elements in the column highlighted above, and for that we will have to travel some more.
I’ll skip to the final solution for this particular column.
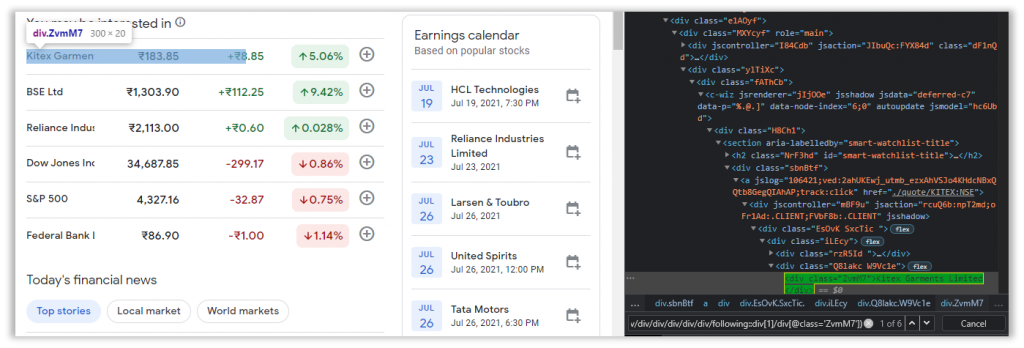
//div[@class='sbnBtf']/a/div/div/div/div/div/div/following::div[1]/div[@class='ZvmM7']This will confuse most of you, so I’ll break it down for you with an example.
If an Xpath is followed by a /tag, that means this particular tag is a child.
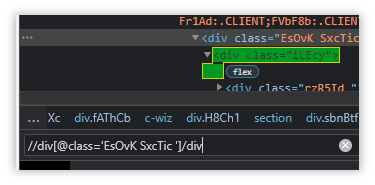
The first div tag with class=‘EsOvK SxcTic ’ is a parent to the second div tag with class= ‘iLEcy’.
So to access it, we may simply append a slash followed by a DIV.
//div[@class='EsOvK SxcTic ']/divBut this recognizes other elements as well, which is why we have introduced anchors.
This way, we can uniquely identify the items we want and it will always return unique matches.
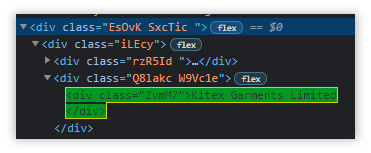
Most of these Xpaths are crafted through trial and error, so it might take a while for you to get a hang of it.
Onto The Last Column
The other columns are extracted in a similar fashion, but this one is a little special.
I faced difficulties extracting data from this particular column, so I will detail the solution for that as well.
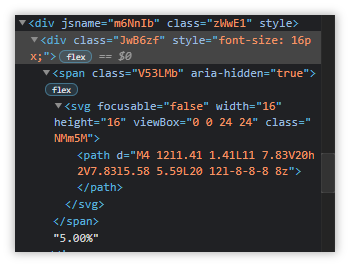
//div[@class='sbnBtf']/a/div/div/div/div/div/div/following::div[10]/div/span[@class='V53LMb']This was able to uniquely identify the item I was interested in, but my bot was unable to extract the data.
I didn’t understand why, so I analyzed the HTML structure, performed more tests, and finally figured out what the issue was.
We Are Siblings, You and I
If you look closely, you will realize that although the DIV contains one single SPAN, what evaded my notice was the text (which we wanted to extract), didn’t belong to the SPAN.
It is a tagless sibling, and to ensure that it gets detected, we have to append one last segment to our XPath to complete it.
//div[@class='sbnBtf']/a/div/div/div/div/div/div/following::div[10]/div/span[@class='V53LMb']/following-sibling::text()And that is how you capture data, regardless of the tags they are contained within or separated by.
In the next article, we will integrate this solution into our main workflow and configure it to store data as a table.
Amazing Content.. Xpath knowledge is must to figure out hidden tags using custom xpath(absolute path)
Hi Sameer,
Appreciate the feedback!
Let me know if there are any topics in RPA you want me to explore.
Kind Regards,
TCT
Nice site with helpful info!
Can’t ‘//div[@class=’sbnBtf’]/a/div/div/div/div/div/div/following::div[10]/div/span[@class=’V53LMb’]/following-sibling::text()’ be simplified to ‘//div[@class=’sbnBtf’]//span[@class=’V53LMb’]/following-sibling::text()’?
Hi Arvind,
Thank you for your response, and yes it absolutely can, but since this was an introduction I didn’t want to jump into that.
Maybe I can pen another article where I can expand a bit more on Xpaths like the not Function, ancestor etc.
Kind Regards
TCT