
AA: Excel, With Database Operations!

“But TCT, I have never worked with Databases nor has a requirement ever popped up, so why bother learning it?”
Tsk, tsk, tsk.
It’s this sort of attitude TCT is allergic to.
Once you see how wonderful Database Operations are, you too will develop an allergy towards those who state “Database is boring” or “Database is useless”.

We won’t be performing database operations on databases – or atleast the databases you are familiar with.
Then What “Are” You Going To Explore Here?
RPA deals with a lot of data manipulation, whether that data is present in documents, mails, or databases.
LINQ is hands down, the best way to manipulate data, which is why I have written nine posts on that topic alone, and in the process of writing more.
But we can’t use LINQ in Automation Anywhere.

So I set out to find an alternative, and was able to find a replacement (kinda) for it.
Database Operations
“But TCT, we mostly work with data coming from Excel, CSV and APIs, so what is the POINT in learning Database Operations?”
The great thing about Database Operations, is that it can be performed on both Excel and CSV files.
Automation Anywhere allows us to connect with Excel and CSV as databases, which makes it easier for us to manipulate large datasets among other things.
And just like you mentioned, most RPA projects deal with excel/csv automation, so once you nail Database Operations, 90% of RPA projects will be a cakewalk.
A great thing to have at your disposal, wouldn’t cha say?

Why Use Database Operations When We Have two Excel Packages Available?
When the dataset is large, and I’m talking thousands or tens of thousands records, using Excel Actions is probably the worst way to go about automating it.
I recently handled a project where the datasets were in the 20k range.
Looping through each record took forever, so I switched to UI and Keystrokes Automation, which took less time, but had a fabulous failure rate.
UI and Keystroke automations aren’t as robust or resilient. Lightly seasoning your automations with static delays won’t cut it, you have to submerge it under an ocean of static and dynamic delays for it to work as expected.
But lucky for me, I was already aware of database operations and the moment I switched over to database, the processing time went from 20 minutes to under a minute.
RPA is supposed to reduce processing time, not stretch it, and Database Operations are the cheatcodes which will help you get there!
And What About APIs?
I haven’t thought about that yet, but the idea I have as of now is to manipulate the API into comma separated values which I can log to a CSV file and then connect to it like it were a Database.
Sounds great in theory, but I haven’t tested it out yet, so that will be addressed in another article (maybe).
Excel as a Database
To use Excel like it were a database, you have to connect to it like it were a database.
For that, you will have to install the Microsoft Access Engine(32-bit version). V11 only required a Microsoft OLE DB Driver to be installed, but not A360. He is a little more demanding.
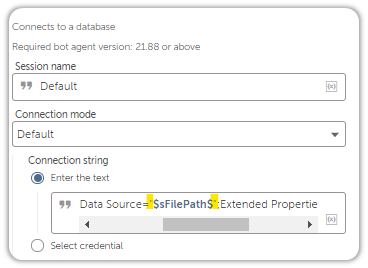
Once the installation is complete, drag in a Database: Connect Action and pass in the Connection String shown below:
Provider=Microsoft.ACE.OLEDB.12.0;Data Source="$sFilePath$";Extended Properties="Excel 12.0 Xml;HDR=YES"Pay attention to the items highlighted above.
Ok, you want to connect to excel, but WHERE is it located?
Ok, you want to retrieve data, but does it contain HEADERS?
Also, everything in the connection string provided above is required. I made the rookie mistake of excluding “Provider=” from the Connection String because I thought the connection string was after the equal to sign.
I blame my Math teacher for conditioning me to think like that.
Basic Query Syntaxes
Want to retrieve the entire Sheet?
You have to Select it.
SELECTSELECT tells the compiler that I want to retrieve items from the data source, which in this case is the excel workbook(we specified that in the connection string itself).
But SELECT what exactly?
SELECT *Asterisk or Wildcards is used when we wish to retrieve everything from the data source, which is exactly what we want right now.
That’s about it for the logic, now we have to select everything FROM the sheet name.
SELECT * FROM [Sheet1$$]When performing database operations on excel, you have to append a dollar sign to the end of the sheet name.
Since dollar signs are treated as variable initializations, its necessary to escape it using another Dollar Sign, which is why you see [Sheet$$] instead of [Sheet1$] which you are used to if you have worked with V11.
Escaping is another way of telling the compiler “I want the dollar sign as the dollar sign, so keep your grubby paws off of it!”
Also, the square brackets are not for decoration, they are a part of the syntax.
What If I Don’t Know What My Column Names Are?
That can be accounted for as well.
You just have to make a small change in the Connection String.
Provider=Microsoft.ACE.OLEDB.12.0;Data Source="$sFilePath$";Extended Properties="Excel 12.0 Xml;HDR=NO"Once you provide HDR=NO, you can’t reference the Columns by their Names but you can, however, reference them by their indexes likes so:
SELECT
[F1],[F2]
FROM [Sheet1$$]F1, F2…Fn, where n is a Natural number.
Natural numbers start from 1, in case you were wondering.

Even though this works, it’s always best to reference columns by their names, and I would recommend sticking to that convention and only use this when there is absolutely no other option available.
If someone decides to add or remove a column or two, then that would mess everything up which is why it’s better to use Header names instead.
Lets look at few more examples and this time we will select few columns, instead of the entire dataset. I have already shown you how that works when you interact with Excel after switching HDR to NO, so you can pretty much predict how we will reference columns when they have names.
There, I just told you how its done.
SELECT
[EMP_ID],[EMP_ADDRESS], [ADDRESS]
FROM [Sheet1$$]You will sometimes see column names enclosed between square brackets, but it is not always necessary to do so. The brackets are important when the column names contain spaces.
But the brackets are compulsory when you connect with HDR=NO.
Also, here is something interesting:
SELECT
DT1.[EMP_ID], DT1.[EMP_NAME], DT1.[ADDRESS]
FROM [Sheet1$$] AS DT1We can assign aliases to the data source!
Oh but wait there’s more.
You can remove the AS keyword and it will still work AS expected.
What, not punny enough for you?
SELECT
DT1.[EMP_ID], DT1.[EMP_NAME], DT1.[ADDRESS]
FROM [Sheet1$$] DT1This might seem redundant right now, but it becomes useful, if not necessary, when dealing with multiple data sources.
Also, aliases can be assigned to the columns themselves, so when you output them to CSV, the names will show up at the header level.
SELECT
DT1.[EMP_ID] AS [Employee ID],
DT1.[EMP_NAME] AS [Employee Name],
DT1.[ADDRESS] AS [Address]
FROM [Sheet1$$] DT1I would recommend enclosing column names in square brackets, just to keep things neat and tidy and slightly claustrophobic.
And yes, the AS is required or it won’t wor- you know what I was going to say.
But what if I wanted to perform complex operations like filtering?
Unfortunately, you can’t DELETE records in excel, but you can SELECT what you want and export that to CSV or Excel.
Filtering is usually achieved through the WHERE operator, as shown below:
SELECT * FROM [Sheet1$$]
WHERE [EMP_ID] = 101;This retrieves all the Columns for those records where the EMP_ID is equal to 101.
Lets have a look at how the same can be achieved through CSV files
CSV as a Database
When using CSV, the approach is a little different.
The “approach”, is reflected in the syntax below:
Driver={Microsoft Text Driver (*.txt; *.csv)}; Dbq=$sFolderPath$; Extensions=csv;The File path is not specified in the data source, instead the Folder path is.
The benefit of this is you may connect to as many CSV files as you want within a single session, provided they are present in the same directory.
But how will I tell the bot that I want to interact with TCT.csv, and not log.csv?
This is how its done:
SELECT * FROM [TCT.csv]In Excel, the sheet was the table, and here the file name itself becomes the table, and you don’t have to specify any dollar signs.
CSVs aren’t greedy, unlike a certain SOMEONE.
But of course, this is not the only connection string out there.
Here is another connection string which works just as well:
Provider=Microsoft.Jet.OLEDB.4.0; Data Source=$sFolderPath$; Extended Properties = "text";Filtering is performed in pretty much the same way:
SELECT * FROM [TCT.csv]
WHERE [EMP_ID] = 101;What About Updating CSV Files?
You can filter using WHERE, but I wasn’t able to UPDATE it.
I tried everything but the damn thing is almost as stubborn as I am.
I am not a database wizard, just an apprentice in the making so it will take a while before I get there.
Until then I will keep casting queries at the CSV file.

I haven’t shown you any complex SQL queries since I am also in the process of learning them.
I thought it would be fun to share whatever I’ve learned so far with the rest of you.
I’ll come up with some complex queries for you to crack your head wide open over in the coming days, so stay tuned.
Very informative!
Hi Gopal,
Appreciate the feedback, don’t hesitate to offer suggestions for improvement.
Kind Regards,
TCT