
Download Files the RIGHT Way

Click here if you wish to skip past my rambling but I will be very hurt if you do.
Downloading files seem easy enough – and that’s because it is.
Nope, no magic or mystery here. Rabbits aren’t popping out of my hat anytime soon because I don’t own a hat, nor can I afford one. What can I say, I’m broke and besides, I’d look silly wearing one.
I’ll walk you through some examples of downloading files faster, with a 100% accuracy rate. I’ve also thrown in a little surprise towards the end – and an explanation of how that works next week.
Downloading files seem easy enough (déjà vu?), when performed manually. It’s as simple as clicking a button, browsing for the folder to store it under and hitting save – but you wouldn’t want to follow the exact same steps while automating it.
You see, the problem with RPA is also the reason why it shines.
.
.
.
.
.
I see that you’ve taken the bait.
Fear not, for everything will be revealed in a moment but before that let’s answer a question nobody asked or is ever going to:
WHERE WERE YOU? (Read this if you have time)
Two words – Pixel Art.
Back in 5th grade, my parents bought me a Gameboy Advance in the hopes that it would motivate me to improve my grades.
It motivated me alright – to spend time away from the books.
I loved the gameplay, but its really the artwork that stood out for me. I was always fascinated by it, but never made the effort to learn it because I didn’t know how or where to start or whether I could even do it. I discovered Aesprite purely by chance around four months ago, installed it, and started doodling away.
Unfortunately, this didn’t get me anywhere, because doodling doesn’t get you anywhere.
You must copy art to understand it.
You don’t become an expert on human anatomy by closing your eyes, imagining what it is and how its put together. Its learnt through repeated observation. This of course, requires serious effort – the sort of effort I clearly didn’t put in, and surprise, surprise, I didn’t get anywhere close to producing anything I could be proud of.

I’d say it’s pretty “cool”…
I’ll see myself out.
If that wasn’t bad enough, I was drowning in work and lost interest. I started putting things off and as you can imagine this affected my desire to write, and just like that four months passed by in a flash.
Forget weed – procrastination is one hell of a drug.
Here’s a little piece of advice – don’t stop whatever it is you are doing. If anything, it’s the momentum which keeps you motivated…
.
.
.
.
.
Unless that something is drugs then please stop and get some help.
Now let’s get back to the topic that seems to keep mysteriously slipping through my hand.
The Problem also Happens to Be its Defining Feature
RPA does what you do manually – but efficiently – but not always.
Don’t get me wrong, RPA does a fantastic job of automating stuff, just not always. Latency issues affect the application performance which in turn affects the process automating it. It also fails if the User Interface doesn’t render properly or if the UI changes. UI changes usually take place during patch updates and the bot won’t recognise the application thanks to her new makeover.
RPA is also in great demand since we can’t expose all APIs. Most APIs are kept private for security reasons which means BPM tools like Workato will have a tough time working with applications that have little to no public APIs.
Optimization is the Key
Designing RPA solutions involve look for shortcuts that reduce UI interactions as it not only helps save time, but also reduces the chances of failure.
Sure, RPA is getting better and better at handling UI interactions, but nothing beats a shortcut, and the best ones happen to be background processes like API calls and command line operations.
Of course, it’s difficult and sometimes impossible to carry out these conversions but wherever we can, we should – especially when downloading files.
Don’t We Have an Action for That Already?
A seasoned RPA developer would probably be familiar with the Download File Action present under the Browser Package but that won’t be of any help if authentication is required to access the file.
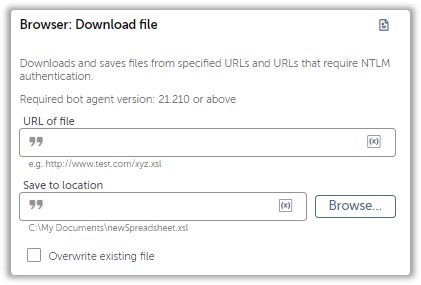
We’ll have to rely on a fancy approach with a fancy package that you can download here. It’s a package that lets you GET and POST files. We will focus on the GET request in this article.
Now before you say “Ugh I already know this, show me something I don’t know.” I am going to show you something you didn’t know before. That being said, I think it’s always a good idea to revisit topics you already know, wouldn’t you agree?

Download Files (Without Authentication)
The Download File Action can get the job done but let’s take a look at the Get File Activity from the HTTP File Request Package.
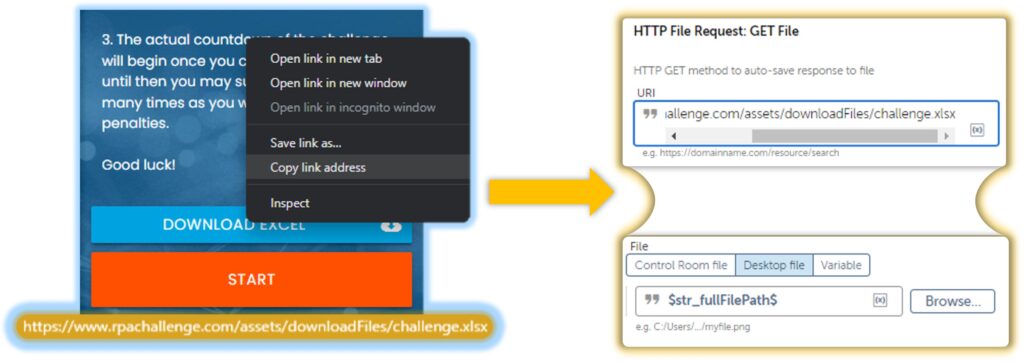
You might be familiar with the RPA challenge page, and if so then you are aware that we must download an excel file before attemptingthe challenge. Since the file is public, we simply pass in the URI and the location to the folder you want to store it under.
But lets be real, most of the files we work with always require authentication – and the Action we explored right now have fields that will help us achieve exactly that.
Lets take a closer look at the HTTPS Get Action:
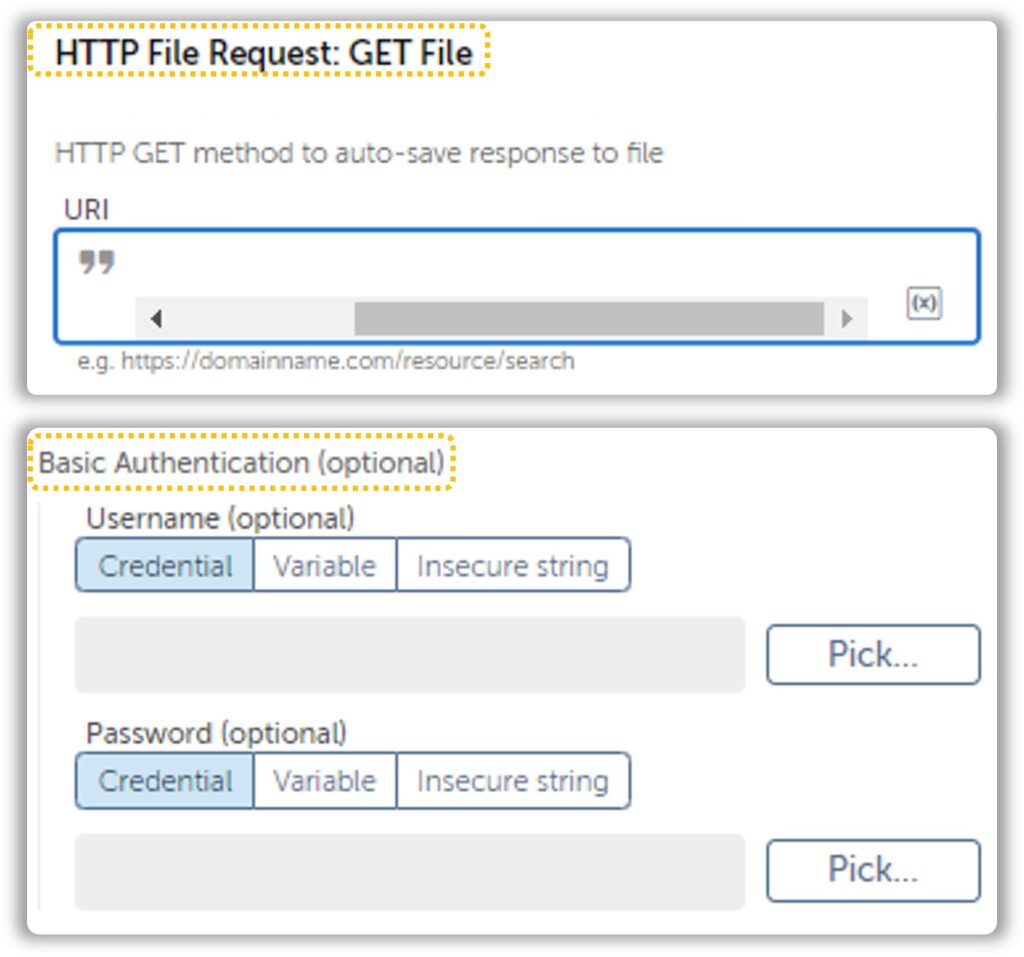
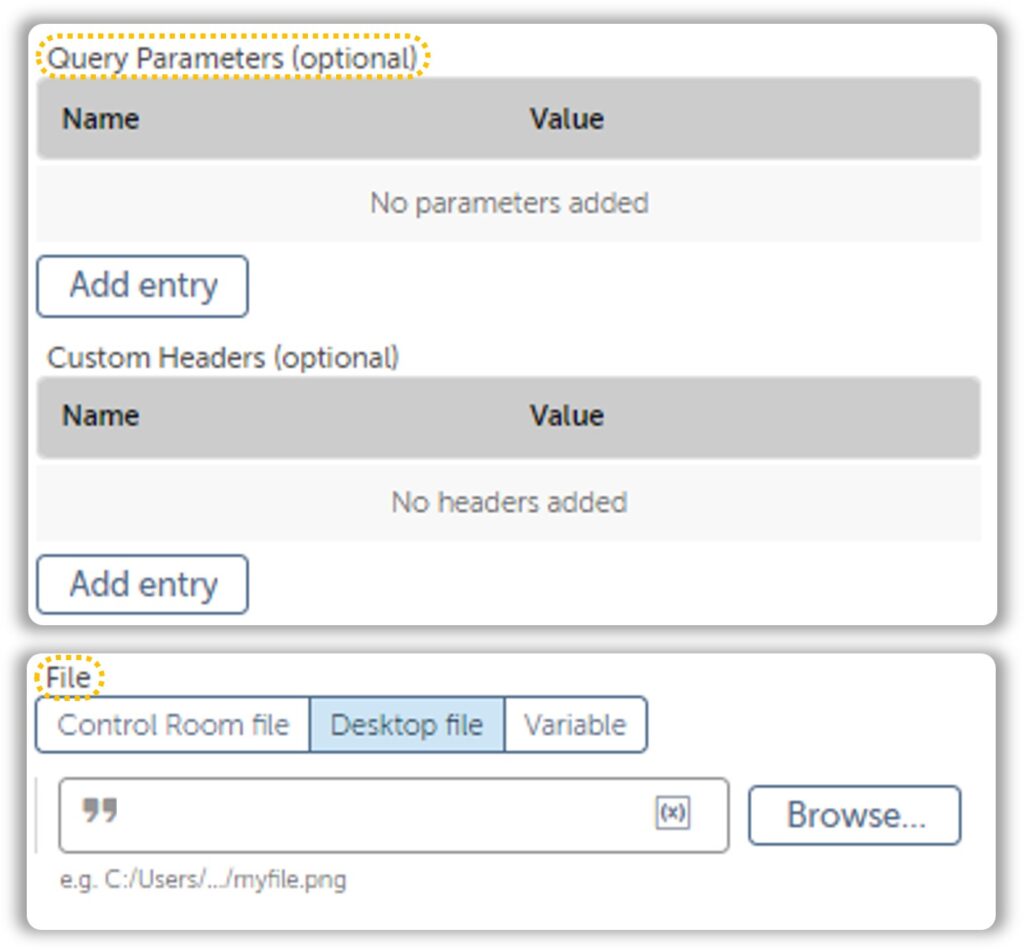
As you can see, the HTTP File Request Action has extra fields that will help us with accessing files hiding behind an authentication. There are times when basic authentication won’t do the trick. We must dig around in the Chrome Developer Networks tab until we find what we are looking for. The latter approach is a bit complicated, but the most rewarding once you get a hang of it.
While this approach sounds great, it might not always be feasible. Downloading files that require OAuth 2.0 or uses JS to create endpoints can be a real pain to work with and I’d suggest proceeding with the UI Approach. Files hidden behind a simple auth are easier to work with.
Its difficult to find websites for practice, so I’ll be walking you through an example which I won’t go into too much detail(because its a client project so hush) in the Networks Tab under Chrome Developer Tools.
Networking with Developer Tools(Chrome)
Usually, most downloadable files are positioned in the DOM within an href attribute like so:

Here is where things get interesting.
Every action you perform on the UI is converted in API calls which can be broken down and analysed under the Developer Tools. This interface is accessed either by pressing F12 or by using the shortcut keys Ctrl+Shift+I.
Another way is by heading over to Settings > More Tools > Developer Tools but you would only do this if you’re a masochist.
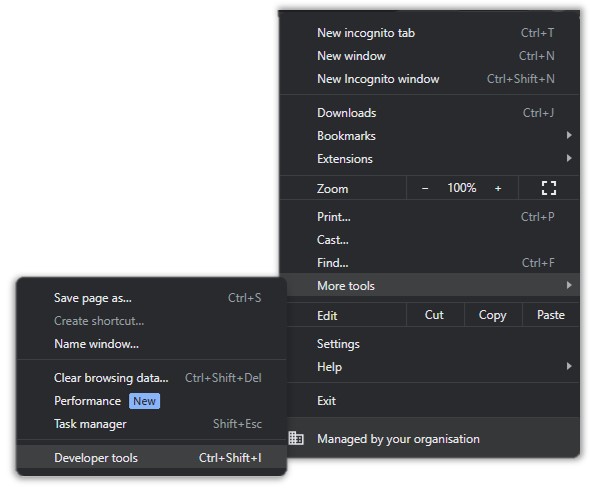
Once you’re there, head over to the Networks Tab:
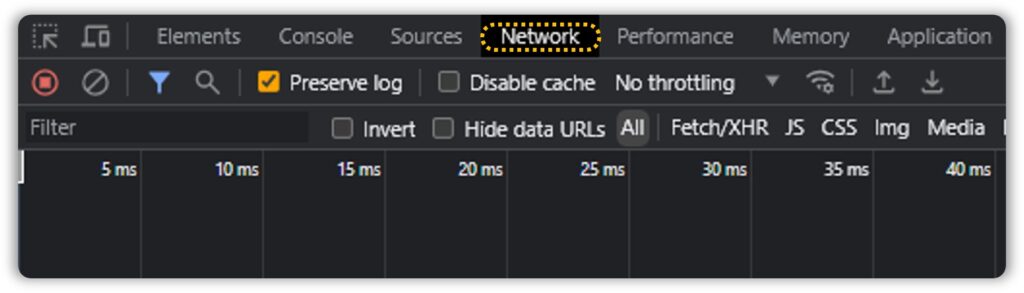
Once we have this set up, click on the download link and watch the console fill up with API calls:
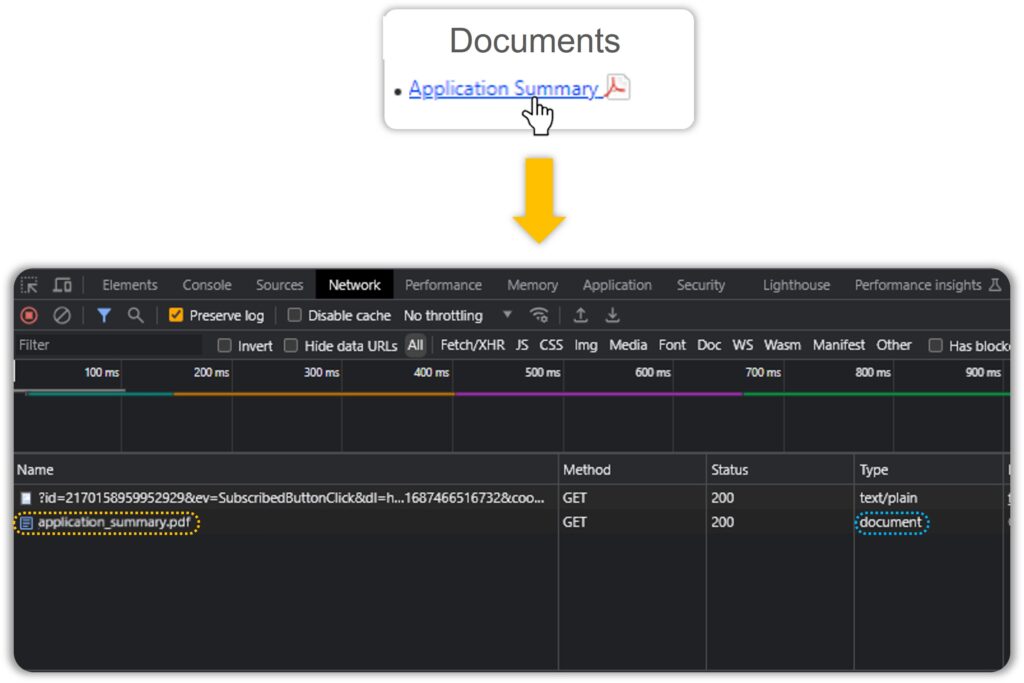
The Networks tab is usually a mess and narrowing it down to the API call(s) responsible for generating our document is something that comes with practice.
.
.
.
.
.
Or you could use the filters present above:
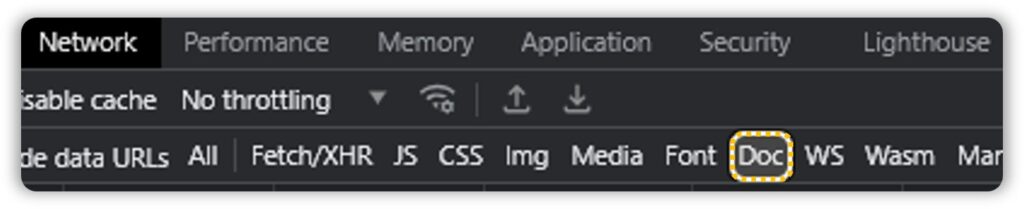
Once we have our API, click on the column and observe the Headers, Response and Cookies. And the best way to do this is by copying the CURL(bash) and Importing it to Postman.
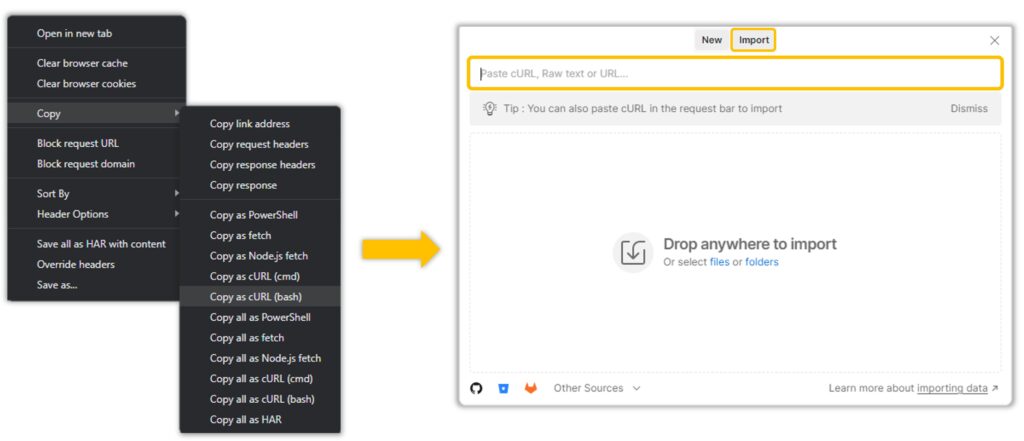
Why Postman?
Postman neatly tucks the Headers and Parameters into dedicated slots like so:
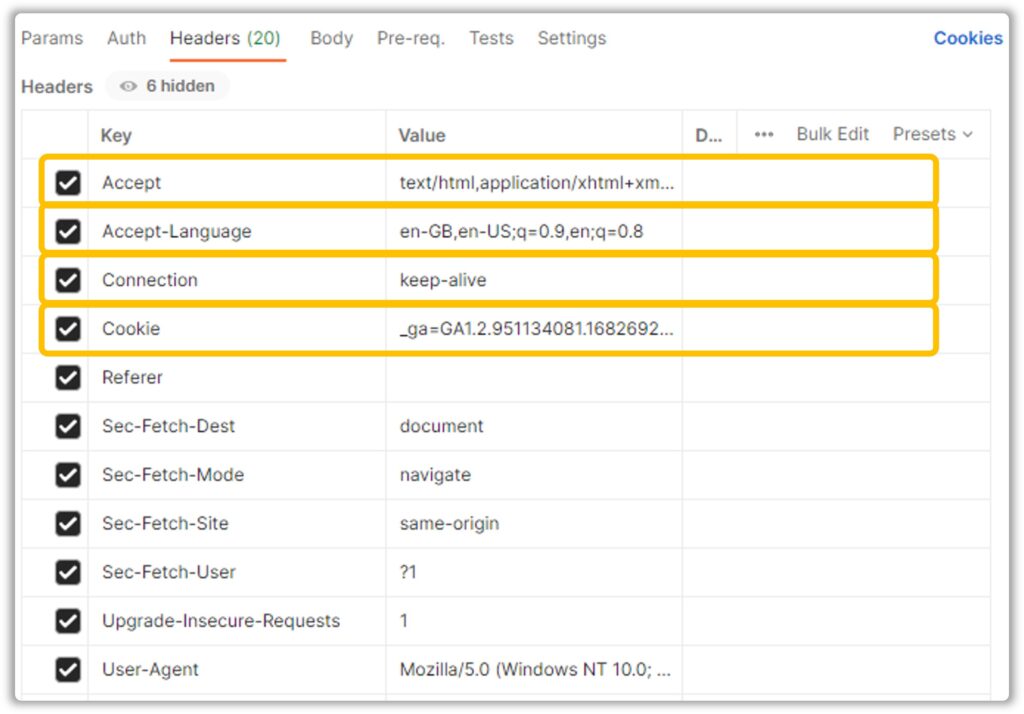
This makes it easier for us to work through the API – figure out which headers are required to make a successful API call. There aren’t any clearcut instructions on how to achieve that – just play around with it long enough and she will reveal her secrets to you.
In this example, only the cookies were required for a successful API call, but how do we retrieve them? It’s not like we have any Actions available to perform this operation so what do we do?
Run a Script, DUH.
JavaScript to be precise.
This can be plugged into the Browser: Run Javascript Action.
function getCookies() {
const cookies = document.cookie.split(';');
const cookieData = {};
for (let i = 0; i < cookies.length; i++) {
const cookie = cookies[i].trim().split('=');
const name = cookie[0];
const value = cookie[1];
cookieData[name] = value;
}
return JSON.stringify(cookieData);
}
But wait there’s more.
The script above works when executed directly in the Developer Console, but not with the Browser: Run JavaScript Action. Automation Anyhwere encases the script within a block of code before injecting it into the browser. This drove me nuts because I didn’t understand what it was, or how to work around it. The documentation was of no help, neither was ChatGPT.
After losing my mind for 3-4 hours, I eventually figured it out.
(function() {
var scriptResponse;
try {
var cookies = document.cookie.split(';');
var cookieData = {};
for (var i = 0; i < cookies.length; i++) {
var cookie = cookies[i].trim().split('=');
var name = cookie[0];
var value = cookie[1];
cookieData[name] = value;
}
var returnResult = JSON.stringify(cookieData);
if (returnResult && typeof returnResult === 'object' && typeof returnResult.then === 'function') {
returnResult.then(function(result) {
scriptResponse = { type: 'executeJavascriptResponse', returnValue: result };
window.dispatchEvent(new CustomEvent('automationanywhere-recorder-ExecuteJs', { detail: scriptResponse }));
});
return;
} else {
scriptResponse = { type: 'executeJavascriptResponse', returnValue: returnResult };
}
} catch (error) {
console.log(error);
scriptResponse = { type: 'executeJavascriptError', errorResponse: error.message };
}
var customEvent = new CustomEvent('automationanywhere-recorder-ExecuteJs', { detail: scriptResponse });
window.dispatchEvent(customEvent);
})();
//Add THAT to the documentation folks.Once we have our cookies in JSON format, they can be processed with the JSON Action Package to fetch the Cookie(s) required for the API call.
All that’s left is to add our Cookie as header and hit the API.
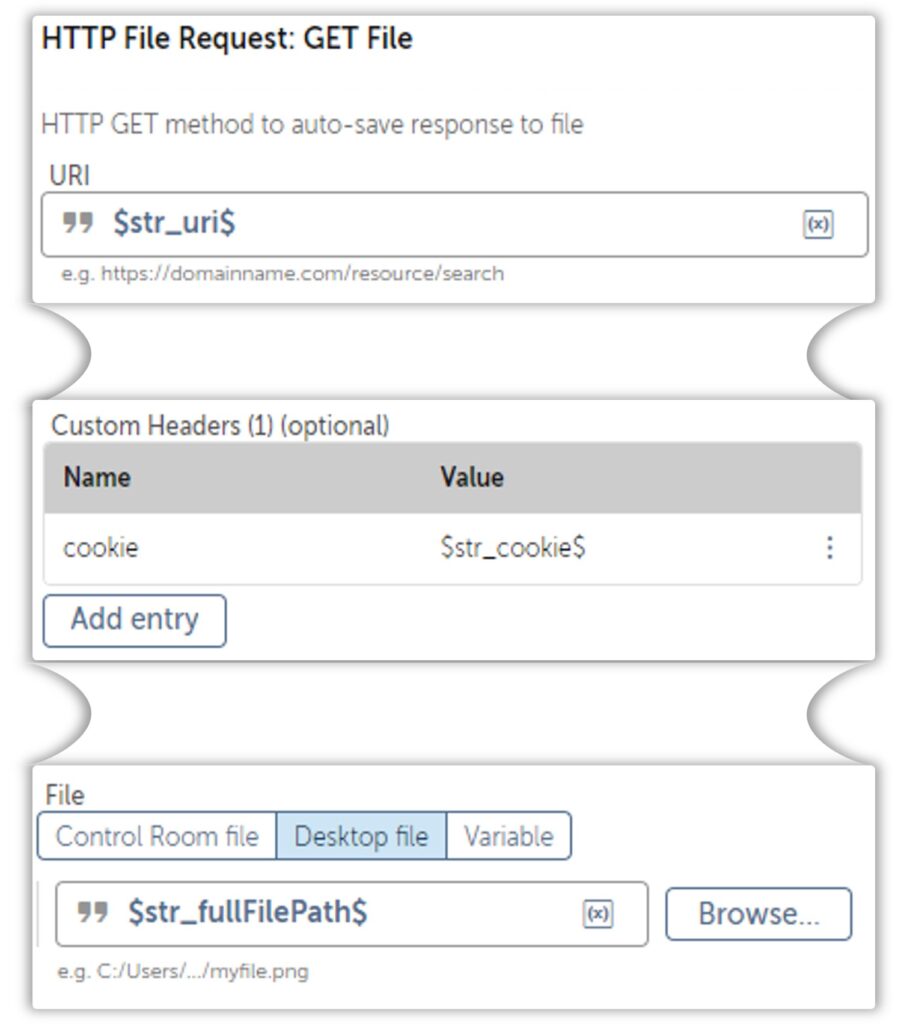
Surprise Time!
Did you know that you can save webpages as PDF?
Did you know that this can also be performed in the background?
Its performed using Chrome Command Line Switches.
--headless --disable-gpu --print-to-pdf="$str_fullFilePath$" "$str_url$"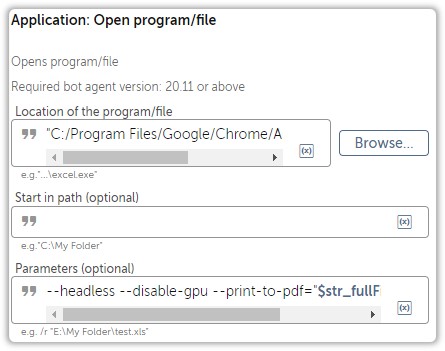
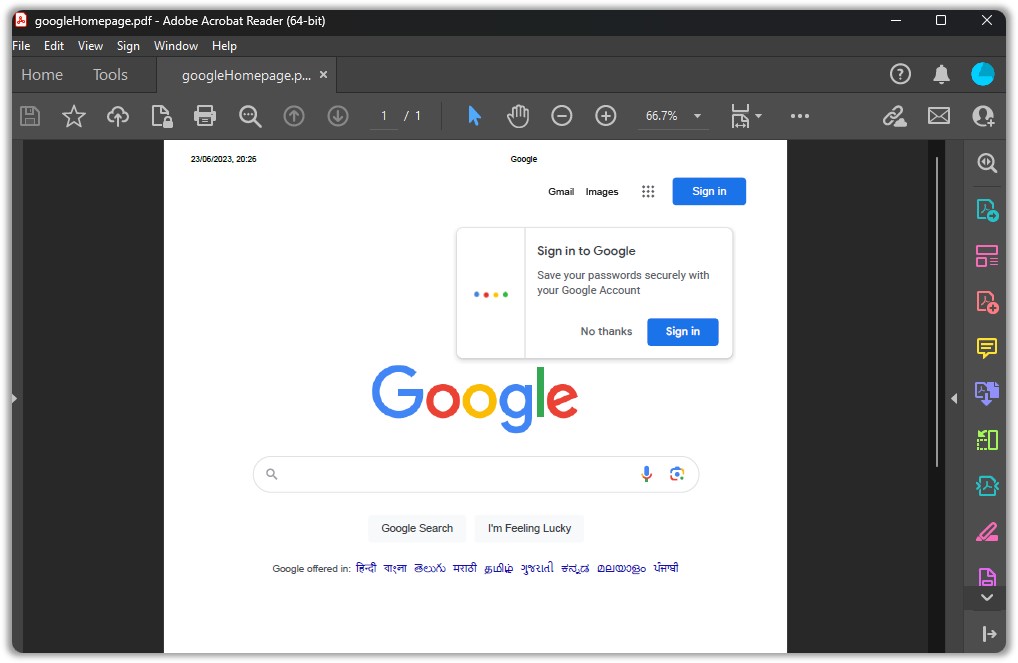
But what if the webpage requires authentication?
Let’s find out next week!