
AA: Show XML Some Love

While HTML displays data on the web, XML stores and transfers data.
Sure, there is a lot more to it than that, but its better to keep things short and simple so that people can follow along and won’t ask any difficult questions.

Ok I’ll be honest, I’m not really that good at XML. Every XML tutorials I’ve watched till date bored me to death, which is why I never explored it in detail.
Also, most, if not all tutorials just showed a sample XML file and ran simple XPaths with the XML Action Package to retrieve values from it.
No excitement there.
I understand that by dissing on the others I have set very high expectations but let me assure you, that you won’t be disappointed with what you are about to read.

XML is Pretty Easy To Work With
I didn’t particularly like XMLs but after exploring it, nothing has changed.

If you’ve worked with XPaths before, then XML is going to be a cakewalk, because XML uses XPaths and XPath Functions.
That being said knowing where all it can be applied is something most of you probably aren’t aware of. I’m guessing most of you have only used the XML Package when reading Configuration Files.
Don’t get me wrong, that is incredibly useful but did you know that you can use it for Web Automation as well?
Well, maybe not web automation in its entirety, but it can aid Web Automation.
We will look at one example in today’s post.
Which Checkboxes Are Checked?
The Recorder Action is an incredibly versatile tool, but it doesn’t always work as expected.
I tried to retrieve the status of checkboxes on this website, but it didn’t return the Status property. I even tried refining the XPath, but that didn’t help either.
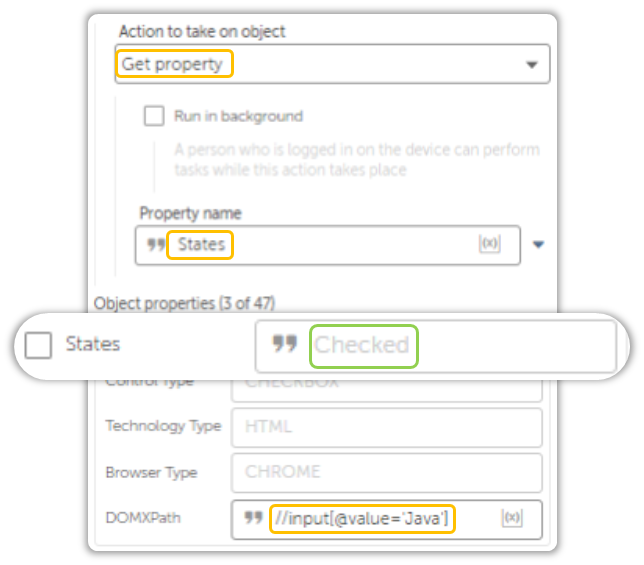
Websites can be really stubborn at times.
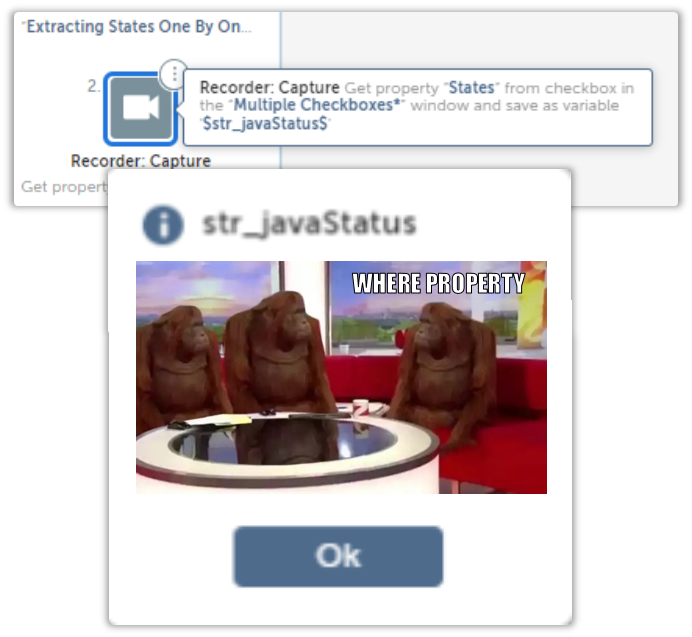
While I was trying to figure out what went wrong, I stumbled upon an interesting property called OuterHTML.
It had HTML in it…which is expected(no duh), but what stood out was that it was structured.
It didn’t appear as a single line of text, instead it retained its indentations.
It looked kinda XML-ish, so I thought to myself,
“This looks kinda XML-ish…maybe I can do something with this.”
You Know, That is Great and All Bu-
I extracted the OuterHTML property and spent a solid hour figuring out why the frikin’ thing wouldn’t get parsed as an XML.
I eventually figured it out.
Sometimes the DOM might not be well-formed, which is a fancy way of saying that some of its nodes may or may not contain closing tags.
HTML is pretty lax when it comes to stuff like this, but XML is not.
XML likes her closing tags very much. She even likes it when you give her a declaration.
This isn’t something a little bit of string manipulation can’t resolve.


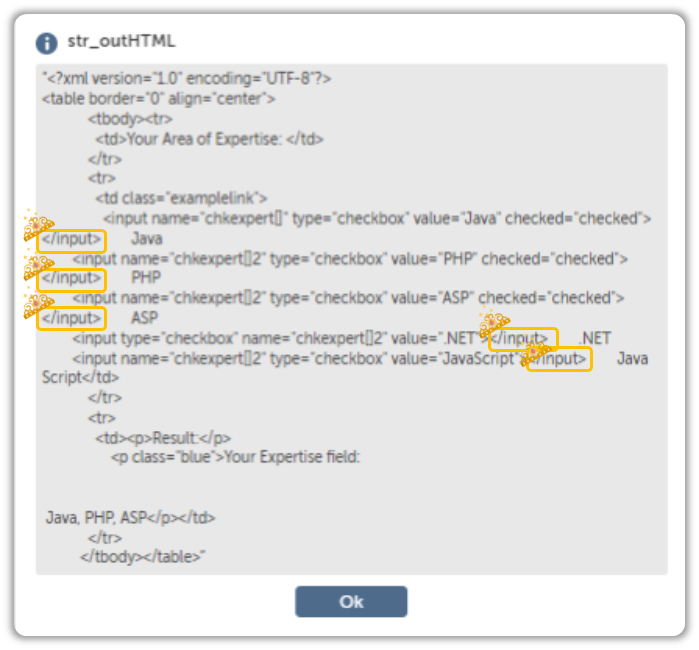
I even squeezed in a Declaration, just to show off.


I See Where You Are Going With This, But There is Something You Need To Kn-
I know, I know.
The closing tags should come after the text value, but I didn’t bother doing that because the goal here was to close the tags so as to obtain a well-formed XML, which is exactly what we did.
Besides, you can also retrieve the values since it is present as an Attribute.
Now for the interesting part.
Sigh, Go On.
I bet most of you might be somewhat aware of XPaths since Web Automation in Automation Anywhere relies heavily on them…but what about XPath Functions?
Don’t worry, there is nothing scary about XPath Functions. It’s just your usual XPath, but it returns stuff, because that is what a Function does.
It returns stuff.
You know.
Might not sound as exciting, but its incredibly useful.
XPaths vs XPath Functions
XPaths are absolute when it comes to detecting elements. Even though an XPath evaluates conditions for matching elements inside those fancy looking square brackets, if it doesn’t find a match, it doesn’t return anything.
The only way to motivate XPaths to return something, is by modifying it into a function.
Here is how we will achieve that.
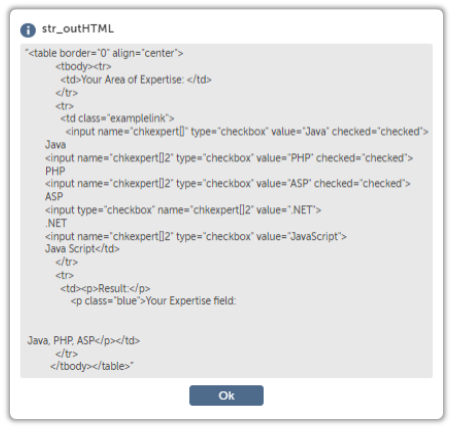
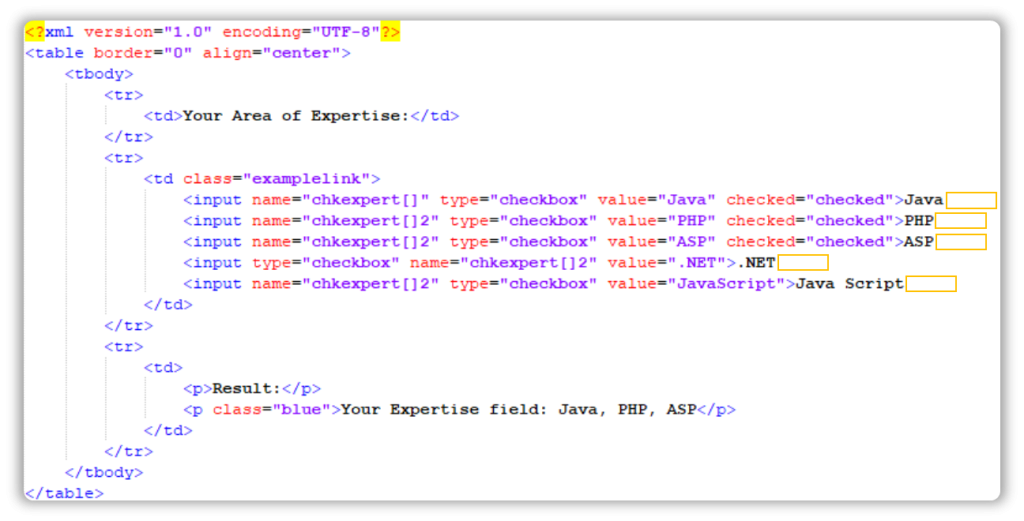
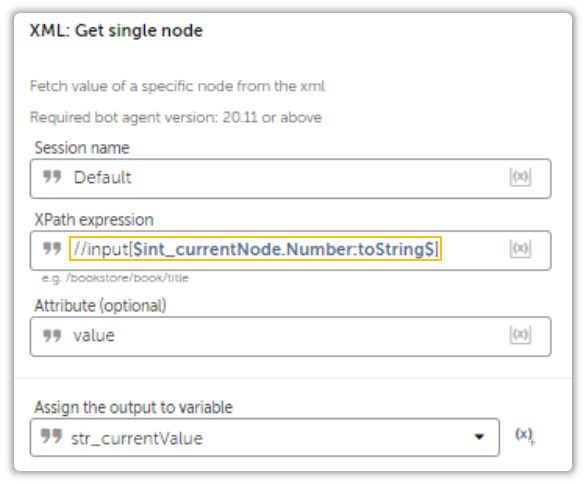
First, we will create an XPath to locate the item of interest. In this case, the items which are checked contain an attribute called checked.
<?xml version="1.0" encoding="UTF-8"?>
<table border="0" align="center">
<tbody><tr>
<td>Your Area of Expertise: </td>
</tr>
<tr>
<td class="examplelink">
<input name="chkexpert[]" type="checkbox" value="Java" checked="checked"></input> Java
<input name="chkexpert[]2" type="checkbox" value="PHP" checked="checked"></input> PHP
<input name="chkexpert[]2" type="checkbox" value="ASP" checked="checked"></input> ASP
<input type="checkbox" name="chkexpert[]2" value=".NET"></input> .NET
<input name="chkexpert[]2" type="checkbox" value="JavaScript"></input> Java Script</td>
</tr>
<tr>
<td><p>Result:</p>
<p class="blue">Your Expertise field:
Java, PHP, ASP</p></td>
</tr>
</tbody></table>The XPath for the node containing Java would be as follows:
//input[@value = 'Java' and @checked='checked']Of course, you have to first study the DOM before you can start creating suitable XPaths.
Then again, its easy to devise a logic to loop through each Node make the value attribute dynamic and fetch values using the XML: Get Single Node Action, but what happens when the checked attribute is not present?
If you try to retrieve a node that doesn’t contain the checked attribute, like in case of .Net or JavaScript, the bot will throw an error.
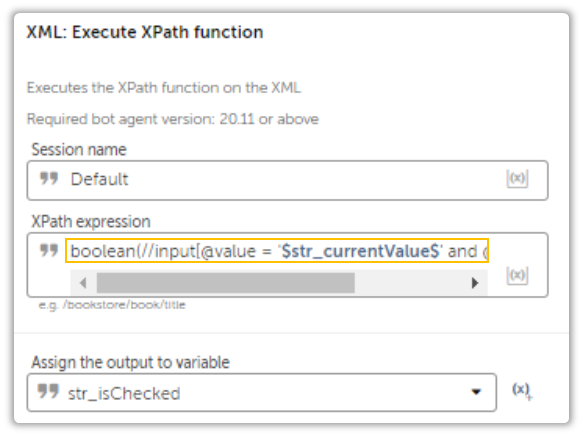
The way to resolve this is by using the XML: Execute XPath Function Action.
boolean(//input[@value = '$str_currentValue$' and @checked='checked'])The Boolean Function will return either true or false. Can’t get any more descriptive than that.
You can get creative with them. For example you can use a Count Function to count the number of Nodes and assign counters like so:
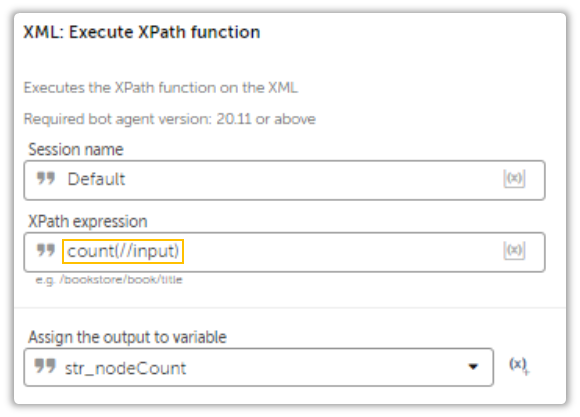
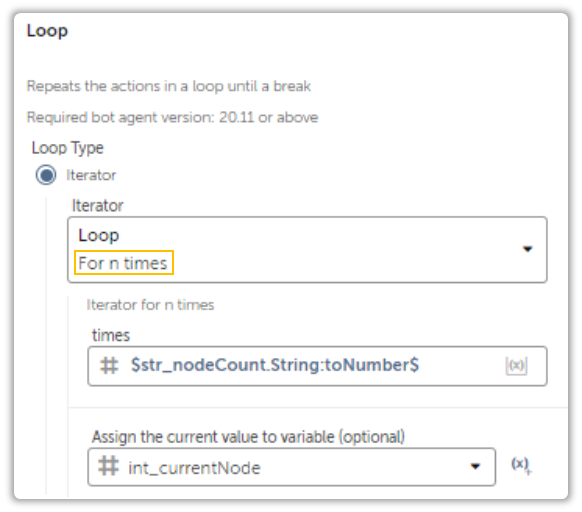
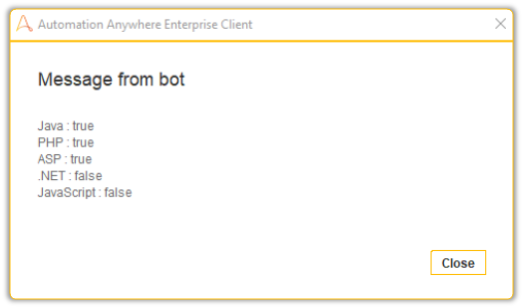
And that is how you do it.
I Hate To Interject, But All of This Was Unnecessary.
Whaddya mean?
The Capture Action Is Smart Enough to Check Boxes Only If Its Unchecked.
Ohh!
I don’t get it.
Check This Out.
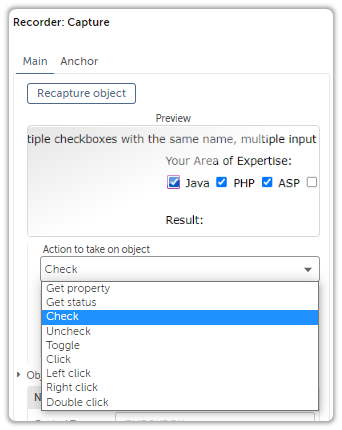
So…Yeah.
Well that doesn’t matter since I wanted to explore XML in a way that would surprise people.
I’d like to think that I did a pretty good job.
Are You Sure? I Mean Your Eyes Are…
No I’m not crying, you are crying!